PROJECT OVERVIEW
한 줄 요약
"금속 현미경 사진을 올리면 AI가 어떤 미세조직인지 자동으로 분류하고,
어느 부분을 보고 그렇게 판단했는지까지 시각적으로 설명해주는 웹 서비스"
📥
데이터 준비
NIST 공개 데이터셋 961장을 클래스별로 정리·분할
🧠
모델 학습
ResNet50 전이학습으로 7개 조직 분류 (1주차)
🔍
Grad-CAM
AI가 어디를 보고 판단했는지 히트맵으로 검증 (2주차)
🌐
웹 앱 & 배포
Streamlit 웹 UI + Docker로 Hugging Face Spaces 배포 (3주차)
2 / 11
LIVE RESULTS
실제 학습·분석 결과
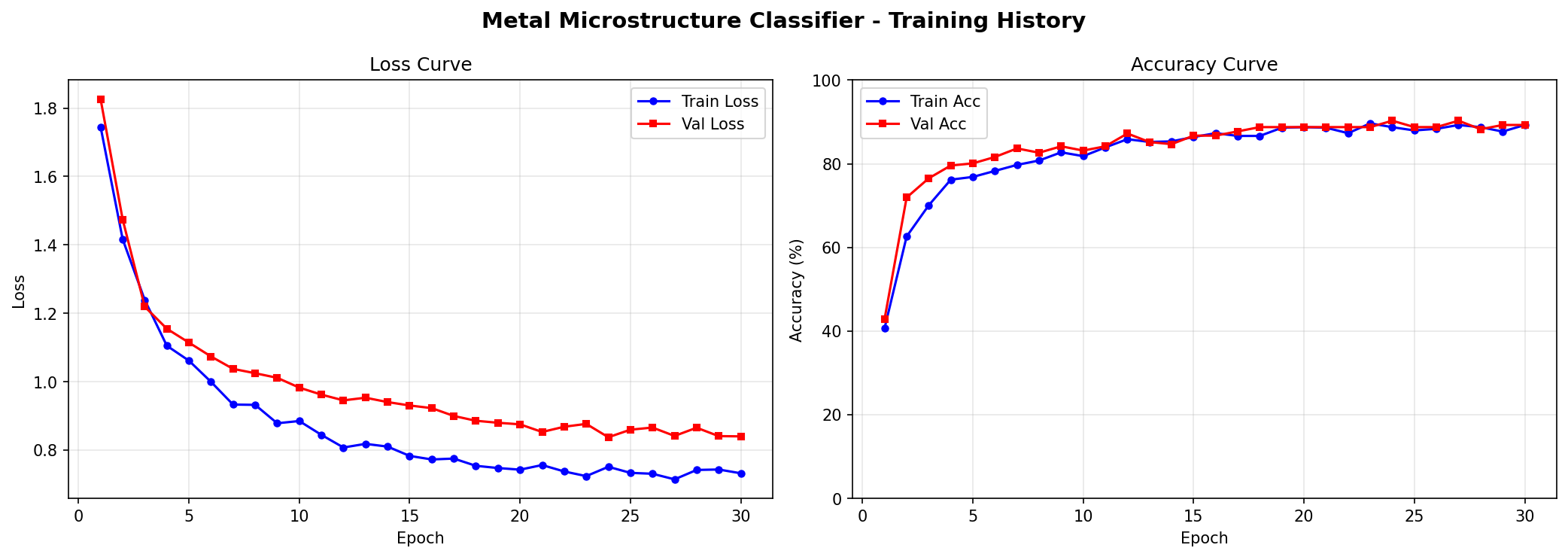
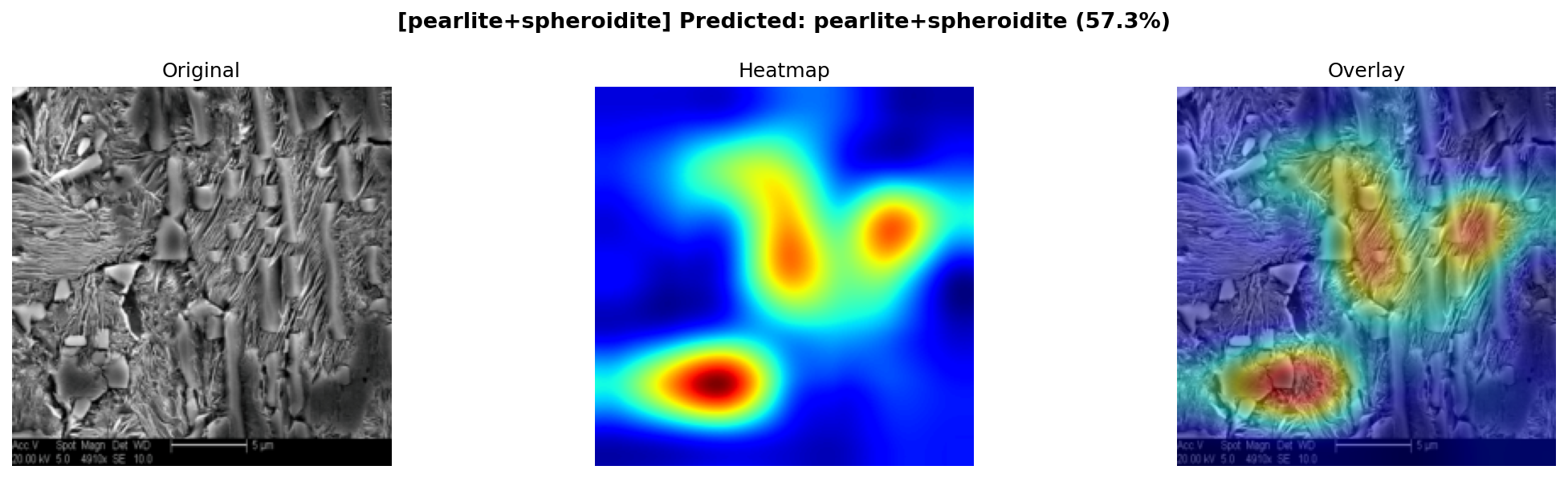
학습 곡선 (Val Acc 90.3%)
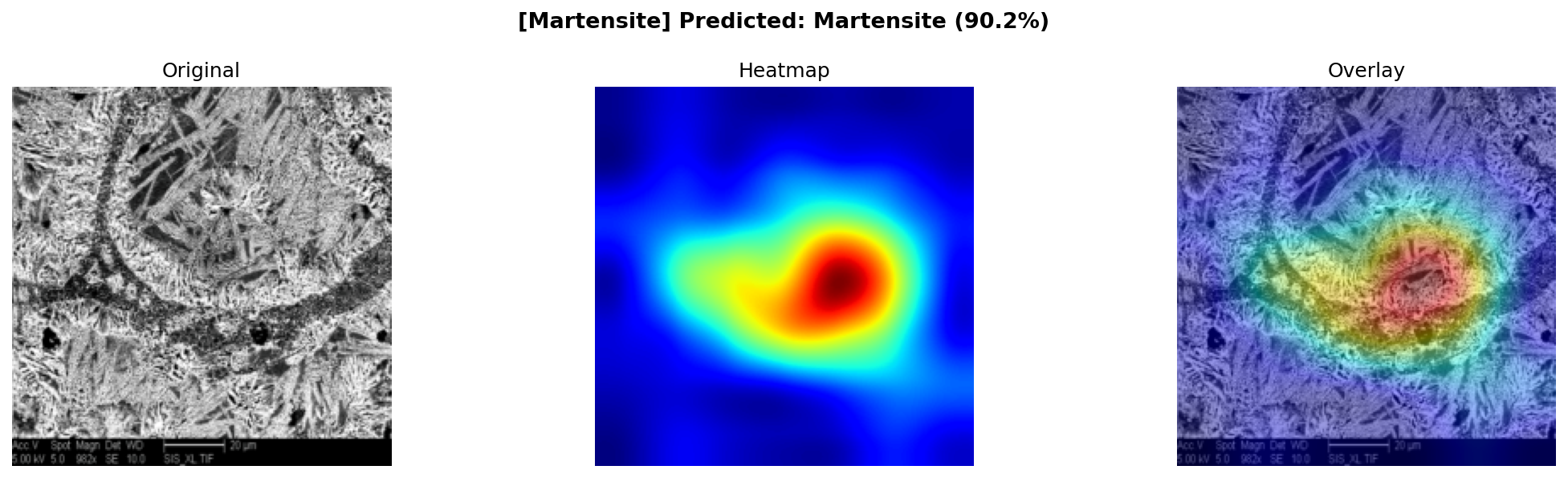
Grad-CAM · Martensite
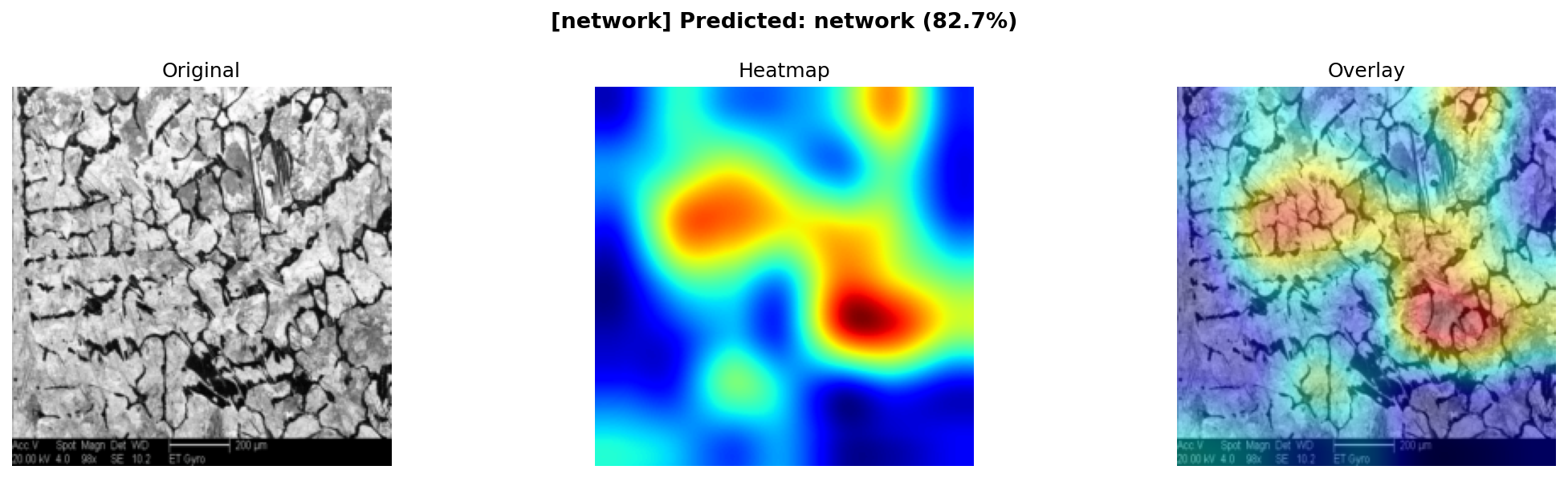
Grad-CAM · network
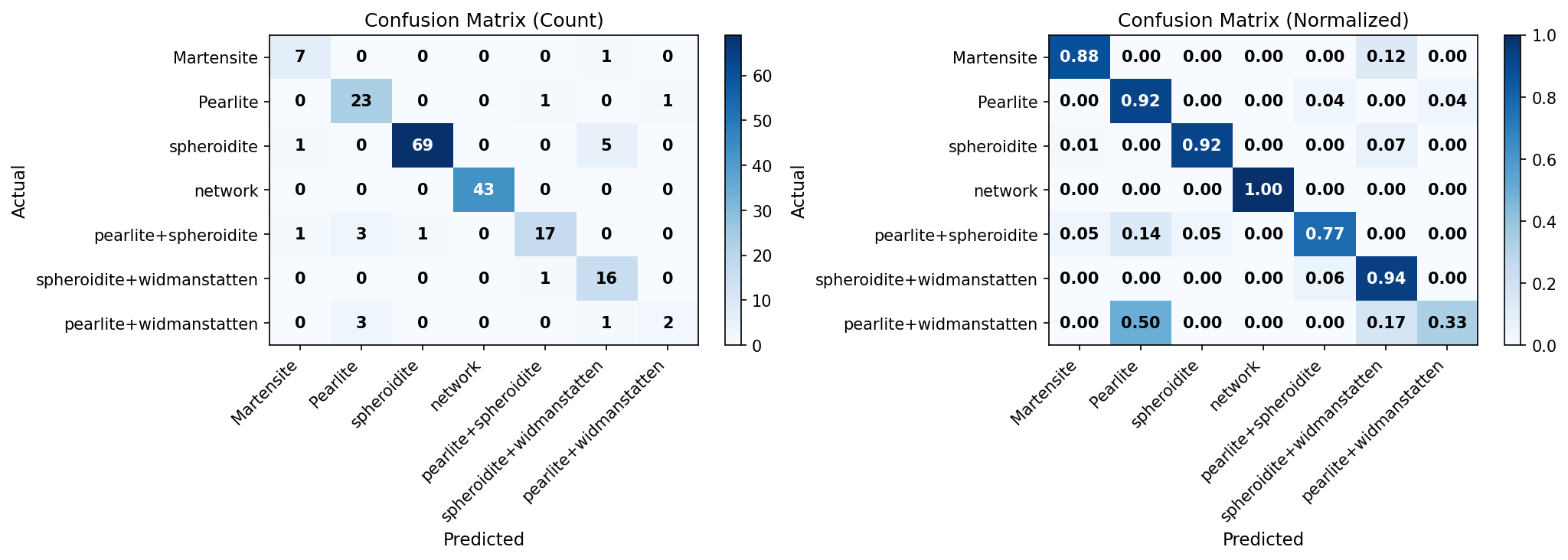
혼동행렬 (전체 90.3%)
빨간색 = AI가 집중해서 본 영역 → 마르텐사이트의 침상(바늘 모양) 구조에 정확히 집중,
금속공학적으로 타당한 부위를 보고 판단했음을 확인
5 / 11
CHALLENGES
어려웠던 점들
처음 해보는 딥러닝 프로젝트라 예상치 못한 문제들이 단계마다 터졌습니다.
🖥️
GPU 없이 CPU로 학습
GPU 없는 환경에서 30 epoch 학습에 약 3시간이 걸렸습니다.
절전모드 때문에 학습이 중간에 끊기는 문제까지 있었습니다.
⚖️
데이터 불균형
스페로다이트는 374장이지만 마르텐사이트는 36장뿐.
클래스마다 학습 난이도가 크게 달랐습니다.
📦
282MB 모델, 배포의 벽
학습된 모델 파일이 282MB — 일반 무료 배포 플랫폼의
100MB 제한을 훌쩍 넘어 처음 선택한 플랫폼으로는 배포가 불가능했습니다.
"정확도 90.3%를 만드는 것과, 그 모델을 실제로 동작하는 서비스로 세상에 내보내는 것은 완전히 다른 문제였습니다."
7 / 11
PROBLEM SOLVING
어떻게 이겨냈나요?
🔴 문제
마르텐사이트 등 일부 클래스는 학습 사진이 36장뿐 — 모델이 제대로 못 배울 위험
→
🟢 해결
회전·색상 변화·블러·잘림 등 데이터 증강(Augmentation)을 적용해 적은 사진도 다양한 조건에서 학습되도록 보강
🔴 문제
전이학습한 모델이 ImageNet에서 배운 일반 지식을 잊어버리고 과적합될 위험
→
🟢 해결
레이어별로 학습률을 다르게 설정(저수준 레이어는 거의 동결, 마지막 레이어만 집중 학습)해 기존 지식은 보존하고 금속 조직 특징만 새로 학습
🔴 문제
282MB 모델 파일 — Streamlit Community Cloud(100MB 제한)에 배포 불가
→
🟢 해결
대용량 모델을 지원하는 Hugging Face Spaces로 전환, Docker로 실행 환경을 통째로 패키징해 어디서나 동일하게 동작하도록 구성
"정확도만 믿지 않고, 데이터의 한계를 먼저 인정한 뒤 그에 맞는 해법을 찾았습니다."
8 / 11
JOB RELEVANCE
이 경험이 직무에서 어떤 의미인가요?
AI/개발 직무가 아니더라도, 이 프로젝트는 아래 역량을 증명합니다.
🧩
문제를 단계로 쪼개는 설계력
"학습 → 검증 → 배포"처럼 큰 과제를 검증 가능한 단계로 나누고,
각 단계의 전제조건을 명확히 했습니다.
→ 기획·프로젝트 관리·QA 직무에 직결
🔎
결과를 의심하고 검증하는 태도
정확도 90.3%라는 좋은 결과에도 "왜 맞췄는가"를 추가로 검증해
신뢰성을 확보했습니다.
→ 데이터 분석·R&D·품질관리 직무에 직결
⚡
새로운 기술의 빠른 습득·적용
비전공자로서 딥러닝·XAI·Docker·클라우드 배포까지
처음 접하는 기술 6종 이상을 독학으로 익혀 실제로 동작시켰습니다.
→ 새로운 환경·도구에 빠르게 적응하는 능력
🧱
한계를 인정하고 대안을 찾는 끈기
데이터 부족, 배포 용량 초과 등 막히는 문제마다
원인을 분해해 현실적인 대안을 찾아 끝까지 완성했습니다.
→ 끈기·문제해결력, 어떤 직무든 필요한 기본기
문제 정의
단계적 설계
데이터 기반 의사결정
자기주도 학습
끈기
신뢰성·검증 감각
기술 수용 능력
도메인 × AI 융합 사고
10 / 11